Amazon Redshift Data Sharing
Share data securely across warehouses without copying data
Benefits
Amazon Redshift Data Sharing
Amazon Redshift data sharing allows you to share data within and across organizations, AWS regions, and even 3rd party providers, without moving or copying the data. Read from and write to the same Redshift databases using multiple data warehouses and extend the ease of use, performance, and cost benefits that Amazon Redshift offers to multi-warehouse, data mesh architectures. Enable access to live, up-to-date data within and across the organization instantly, eliminating multiple Extract, Transform, Load (ETL) pipelines, enabling collaboration on data, and reducing time to insights. Additionally, it allows you to use multiple warehouses of different types/sizes for ETL so that you can tune your warehouses based on your write workloads’ price-performance needs. With integration into AWS Data Exchange, AWS’s marketplace housing thousands of 3rd party data sets, Amazon Redshift users can easily and securely license 3rd party data sets to combine with the data in their Redshift databases for holistic analysis and power new data monetization opportunities.
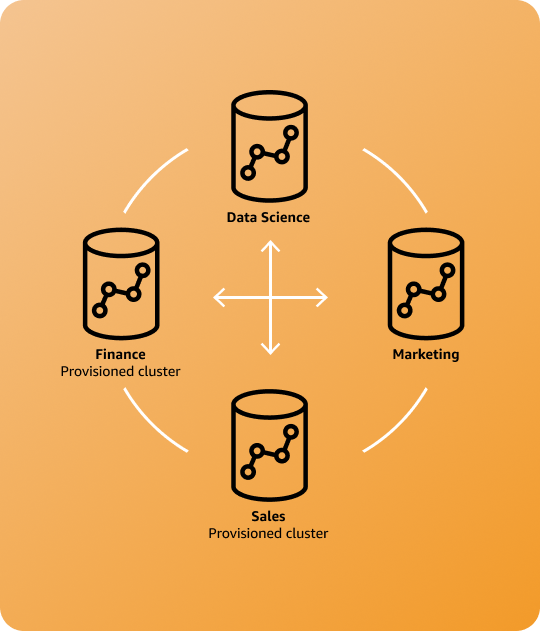
Use cases
Workload isolation and chargeability

Cross-group collaboration

Data and analytics as a service

Development agility




